标签:#SDK数据 #SDK数据采集 #用户行为分析 #用户画像 #数据合规
适合读者:老板/产品负责人/增长负责人/CTO/运营负责人/采购/法务
很多企业接入SDK以后,仍然看不懂用户行为。报表里有PV、UV、点击量、注册数、转化率,但产品负责人很难判断用户到底卡在哪一步,运营负责人也很难判断一次活动为什么带来了访问,却没有带来成交。
问题往往不在于有没有接SDK,而在于有没有把SDK埋点方案设计清楚。SDK数据采集不是简单记录“有人点了按钮”,而是要用事件、属性、用户ID和会话,把分散的用户动作整理成可分析、可追踪、可验收的数据结构。
同时,SDK数据采集必须先讲清合规边界。任何用户行为分析、用户画像和标签体系建设,都应限定在企业自有业务场景中,并在用户授权、隐私政策告知、最小必要原则、数据脱敏和权限控制前提下开展。
一、核心概念:先把SDK数据说清楚
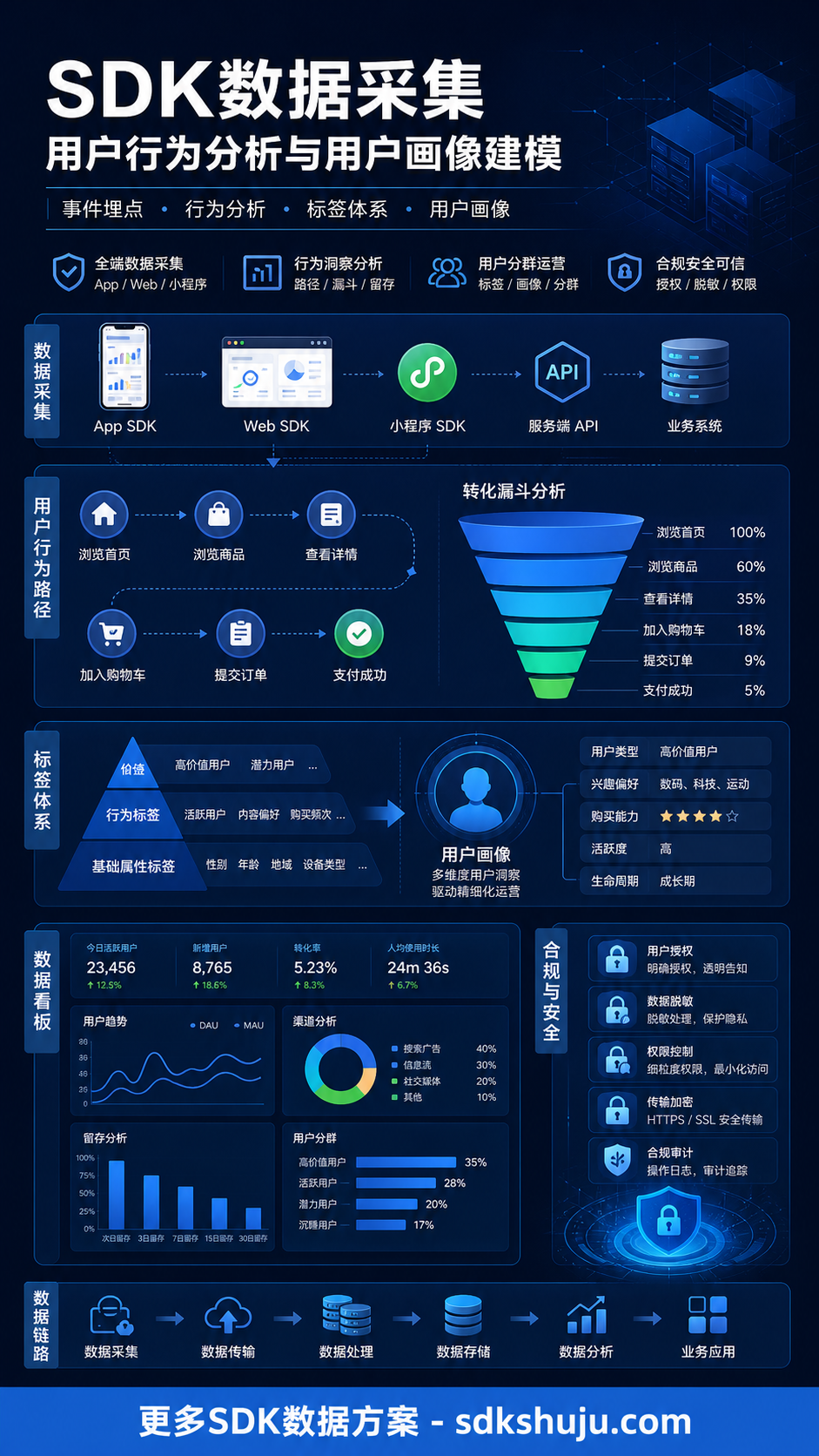
SDK数据是什么?从企业分析角度看,它通常指通过App SDK、Web SDK等方式,在用户使用产品、浏览页面、点击功能、提交表单、完成转化等过程中形成的行为数据。
SDK埋点,就是在产品关键位置设计数据采集点。当用户触发某个动作时,SDK按照预设规则记录事件,并把事件名称、发生时间、用户标识、会话信息和相关属性一起上报到分析系统。
例如,一个电商类页面中,“浏览商品详情页”可以是一个事件;商品ID、商品类目、页面来源、App版本、入口位置可以是事件属性;用户ID用于关联同一个用户的不同行为;Session用于判断这些行为是否属于同一次访问过程。
如果企业需要系统建设这类能力,可以在理解基础概念后,再进一步查看SDK数据采集解决方案,判断自身业务是否需要App SDK、Web SDK、事件模型、用户ID体系和数据分析能力的组合。
二、采集链路:数据从哪里来,又如何进入分析系统
一套相对完整的SDK数据采集链路,通常会经历初始化、事件触发、字段组装、数据上报、服务端接收、清洗校验、入库建模和报表分析几个环节。
企业在项目中经常遇到的问题是:技术团队认为SDK已经接入完成,业务团队却发现报表无法使用。原因可能是事件命名不统一、字段缺失、用户ID没有打通、会话口径不清楚,或者关键转化步骤没有被采集。
所以,SDK埋点方案不能只写“采集点击、浏览、注册、支付”。它需要明确采什么、为什么采、字段怎么定义、谁来维护、数据如何验收,以及是否符合用户授权和隐私政策告知要求。
| 环节 | 关注重点 | 常见问题 |
|---|---|---|
| SDK初始化 | 接入环境、版本、配置项 | 测试环境与生产环境混用 |
| 事件触发 | 页面浏览、按钮点击、表单提交、支付完成 | 关键动作漏埋或重复触发 |
| 字段组装 | 事件名称、时间戳、用户ID、会话ID、属性 | 字段类型不一致、枚举值混乱 |
| 数据上报 | 上报成功率、延迟、失败重试 | 弱网环境下数据丢失 |
| 清洗入库 | 去重、校验、脱敏、异常处理 | 脏数据影响报表判断 |
| 分析应用 | 漏斗、留存、分群、标签、画像 | 报表有数据但无法支持决策 |
三、事件模型:埋点、属性、用户ID和会话如何配合
事件回答“用户做了什么”。常见事件包括页面浏览、按钮点击、搜索、注册、登录、提交表单、加入购物车、完成支付、使用某个功能等。
属性回答“这次行为发生在什么条件下”。同样是点击按钮,属性可以说明按钮所在页面、按钮位置、入口来源、业务对象ID、商品类目、App版本、设备类型等上下文。
用户ID回答“是谁或哪个账号主体做的”。在实际项目中,企业需要区分匿名ID、登录用户ID、业务账号ID、设备标识和会话ID,避免把不同层级的标识混在一起使用。涉及个人信息时,应优先采用脱敏、匿名化或最小必要处理方式。
会话,也就是Session,用来判断一组行为是否属于同一次连续访问过程。比如用户从首页进入,浏览商品,点击按钮,提交订单,这一连串行为可能被归入同一次会话,用于路径分析、转化漏斗和留存分析。
在做用户行为分析解决方案时,事件、属性、用户ID和Session需要统一设计。如果事件没有属性,分析只能停留在次数统计;如果没有稳定的用户ID体系,用户分群和留存分析就很难准确;如果会话口径不清楚,路径分析也容易失真。
- 事件名称要稳定、可读、可维护,避免同一行为出现多套命名。
- 事件属性要有字段字典、字段类型、枚举范围和采集目的。
- 用户ID体系要区分匿名访问、登录状态、账号体系和业务主体。
- Session规则要说明超时、前后台切换和跨端口径。
- 所有采集行为都应限定在用户授权、隐私政策告知和最小必要原则内。
四、业务价值:企业真正需要的是可用的数据判断
SDK埋点的价值,不是让后台多几个报表,而是帮助企业回答真实业务问题。
老板关心的是增长有没有依据,产品负责人关心的是功能是否被使用,运营负责人关心的是活动是否有效,技术负责人关心的是数据是否稳定,采购和法务关心的是方案是否可交付、可验收、可合规。
通过SDK数据采集,企业可以把用户从访问、注册、浏览、点击、下单到复购的过程拆成可分析的行为链路,再结合转化漏斗、留存分析、用户分群和标签体系,判断业务问题发生在哪里。
例如,注册转化率低,不一定是流量质量差,也可能是表单步骤过长、验证码失败率高、按钮位置不清晰,或者某个版本存在异常。行为数据分析的意义,是让团队从“感觉用户不喜欢”走向“知道用户在哪一步流失”。
当行为数据沉淀到一定阶段,还可以为标签体系建设与用户画像建模提供基础。这里的用户画像不是标签越多越好,而是围绕业务目标建立可解释、可维护、可合规使用的用户分层。
五、常见误区:不要把接入SDK等同于完成数据建设
第一个误区,是认为“SDK接入完成”就等于“数据建设完成”。实际上,SDK只是采集工具,真正决定数据价值的是埋点方案、事件模型、字段规范、ID体系、数据清洗和分析口径。
第二个误区,是采集范围过宽。企业不应把“能采集”当成“应该采集”。SDK数据采集应围绕企业自有业务场景,在用户授权和隐私政策告知前提下,采集实现分析目的所必要的数据,并做好数据脱敏和权限控制。
第三个误区,是只看报表数量,不看报表是否能支持决策。一个项目交付了很多报表,但如果字段不完整、口径不统一、转化漏斗无法复现、留存分析无法解释业务问题,这类报表很难真正服务增长。
第四个误区,是忽略验收。SDK埋点项目需要看上报成功率、数据延迟、字段完整性、异常监控、权限控制、审计日志和SLA交付,而不是只看演示阶段的功能截图。
第五个误区,是把合规放到项目最后。涉及用户行为分析、用户画像、标签体系和数据服务采购时,合规审查应在方案设计阶段就参与,而不是等SDK上线后再补隐私政策说明。
六、评估建议:企业启动前应该先问哪些问题
企业启动SDK埋点方案前,建议先把业务目标、技术范围、合规边界和交付标准写清楚。尤其在数据服务采购、POC测试和SLA交付阶段,越早明确规则,后续争议越少。
可以先问这些问题:
- 我们最想通过SDK数据采集解决哪个业务问题?注册转化、购买转化、功能使用、留存,还是用户分群?
- 哪些事件是必须采集的?哪些字段是报表和分析必须依赖的?
- 匿名ID、登录用户ID、业务账号ID和Session ID如何设计?
- 是否已完成用户授权、隐私政策告知、最小必要评估和数据脱敏设计?
- POC测试如何验收?是否检查埋点准确性、数据延迟、上报成功率和字段完整性?
- 权限控制、RBAC、审计日志、SLA响应和项目验收文档是否写进交付范围?
在实施层面,企业可以结合服务实施说明明确项目阶段、交付物、验收口径和协作方式;涉及用户授权、数据脱敏、信息保护和合规说明时,也应提前阅读隐私政策与信息保护说明,并让法务、合规负责人和安全团队参与评审。
如果业务已经进入行业化运营阶段,例如教育、内容、电商、工具、企业服务等场景,还可以结合行业数据分析解决方案梳理关键行为、转化链路和留存指标,避免埋点方案只停留在通用页面统计。
一个成熟的SDK埋点项目,最后交付的不是“装好了SDK”,而是一套可以被业务理解、被技术维护、被合规审查、被数据团队持续使用的分析基础设施。
如果企业正在评估SDK数据采集、用户行为分析、标签体系或POC测试,可以先查看相关服务页,了解实施方式和验收边界,再通过预约方案沟通确认当前阶段适合从哪些核心事件开始建设。